 Search
Search
Why the world struggles to productionalise ML-Driven solutions (MLOps Part 1)
The data scientists working on versioning of the models, deploying, operating, monitoring, or in other words, doing MLOps practices take it as a challenge as it is a complex and laborious process. With the development of the technologies, the machine learning lifecycle has been developed as well. Now the application's logic is no longer captured in the code created by the software developer but reproduced by the ML model trained by the data scientist. And as the same problems occur repeatedly, the engineers working with AI-powered products have built an array of frameworks and tools for developing each new product based on machine learning.
Whether we are talking about self-driving cars, QR code readers, personalised feed on YouTube or approvals of loan requests — machine learning models are more and more often driving automation and “smart” decisions behind. Indeed, building such solutions is a complex but extremely exciting task. No wonder “data scientist” is considered the sexiest job of the 21st century, and the field is attracting many people — the idea of letting data solve the world’s challenges is just so intriguing.
A Wake-Up Call for Everyone in the Data Science Industry
But the truth is that enterprise-grade data science is difficult. Actually, it is enormously difficult. Model versioning and deployment, operating and monitoring — the set of so-called MLOps practices — is often cited as one of the biggest challenges of the ML arena, along with the interconnected DataOps.
In this article, we give our perspective on why that is the case. And what it really takes to make data science bring a real impact on organisations — all through the lens of DataSentics experience.
Are Schools Preparing Us for the Data Science Reality?
Most data scientists joining DataSentics have a technical background — a degree in math, statistics, or physics. They have a solid mathematical foundation — ranging from linear algebra and calculus to probability theory and statistics. Need to find eigenvalues? Easy! Define Taylor’s polynomials or prove Bayes’ theorem? No problem!
Those newcomers are often familiar with machine learning terminology and techniques, have enough programming skills for basic scripting. They are well capable of examining the model statistics (t-test, F-test, R-square) and pointing at which feature is important and how it drives the target variable.
Apart from theory, schools often teach solving entertaining but highly artificial assignments. For instance: “Train a model that will output a house price based on its square footage, number of windows, and colour of the wall”. Such tasks, meant to illustrate a method or a principle, are often the only practice students get in touch with during the school years. Obviously, training of such toy models is done on a local computer and often on top of a small nicely-prepared dataset. The output is usually a report and/or code, which will be assessed by a teacher or even evaluated automatically.
To the best of our knowledge, very similar experience data science enthusiasts could gain by taking MOOCs. At the end of the day, fresh graduates experience only the tip of the so-called “Data Science Hierarchy of Needs”, as defined by Monica Rogati in this post.
The Data Science Hierarchy of Needs
Kaggle and Other Side-Projects
Data enthusiasts understand well that dry theory is not enough and seek out-of-classroom data science experiences. Here, platforms like Kaggle come into play.
Kaggle challenges participants to solve an actual problem using real-world data of medium to large size. No one judges the beauty of the submitted code nor asks to actually deploy a model. Participants, however, must ensure that results are reproducible within the Kaggle server and that the model fulfils (often strict) validation criteria. There is no right or wrong approach, and scientists have the time and space to experiment and be creative. They are highly motivated and encouraged to cooperate within and outside of their team.
The dark side of the moon is that a winning solution is often a high complexity model (especially if data is large), or even multiple models ensembled together. This is because solutions are scored and compared based on the model performance - a single in-advance defined metric. We may face a similar “criteria” of evaluation working on a research project or an academic thesis. In reality, though, there is a bunch of factors making a model THE model, such as interpretability, scalability, development and operational costs, and many others.
Enterprise-Grade Data Science
Sooner or later, the industry unravels an entirely different view on data science for its newcomers. There, ML-code itself is just a tiny fraction of an ML-driven system. There are no artificial tasks nor in-advance defined performance metrics. But there is noisy, unavailable, unlabeled, biased, too big, or too small data from different sources and in various formats. In fact, data is considered the biggest bottleneck for AI adoption in enterprises, according to multiple sources [1][2][3]. And last but not least, there is an ultimate goal that many data scientists up to this point face for the first time in their career, which is productionalisation of the model.
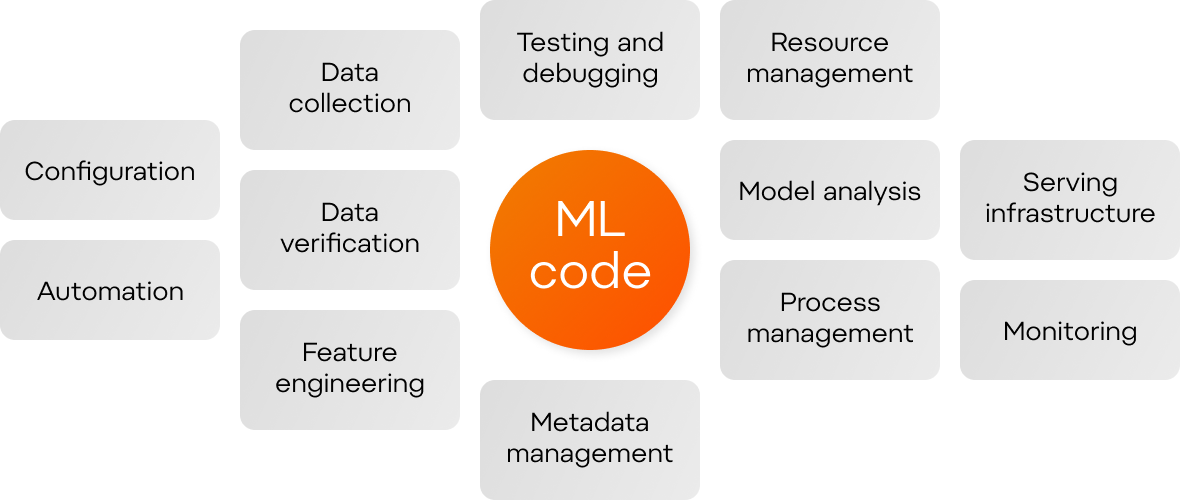
Enterprise-grade ML-driven solution components (based on cloud.google.com)
Indeed, to bring true impact, companies need to be capable not only at developing but also at delivering data-driven solutions as well as at establishing and managing data and model-related operations. This is tricky to achieve (especially from scratch) as a specific cross-discipline skill set and collaboration between multiple teams are required. As it is concluded based on the results of the CIO.com survey of 200 executives on the topic of AI adoption
80% of teams cite collaboration as a challenge with technology skills gaps and project management and oversight as the primary drivers of this divide — resulting in communication breakdowns and friction that slow productivity.
As companies are only maturing toward MLOps, they tend to underestimate or even overlook related costs and complexities. That leaves teams responsible for productionalisation (which often are data scientists themselves) unarmed and exhausted. As many data scientists face challenges for the first time, they struggle to communicate them with other teams, establish collaboration, and even approach the technical complexity.

Indeed, another key finding of the survey mentioned above is the importance of a unified approach to data and model workflows, expecting as top outcomes a dramatic increase in operational efficiency, time to market acceleration, and boost in both business and technical decision-making efficiency.
As we can see, there are multiple reasons why enterprise-grade data science is hard, but there is one crucial outcome — companies are struggling to adopt data driven-solutions. Putting these statements into numbers, 2020 State of Enterprise Machine Learning survey reports
- 55% of [interviewed] companies say they haven’t yet deployed a machine learning model (up from 51% of companies last year).
- 50% of [interviewed] companies say they spend between 8 and 90 days deploying one model. And 18% of companies are taking longer than 90 days — some spending more than a year productionising!
- 41% of [interviewed] companies say the second most difficult challenge with ML is the versioning and reproducibility of models.
The Wake-Up Call
The challenges mentioned above are major and require awareness. Fortunately, the community realises the MLOps and the DataOps importance and complexities and actively invests in them. Algorithmia in 2020 State of Enterprise Machine Learning reports, based on the comparison with data from 2018, that
- Machine learning operationalisation (with a deployed ML lifecycle) is fledgling but maturing across industries, with software and IT firms leading the charge.
- The number of data scientist roles at companies is often less than 10 but grows rapidly across all industries.
New roles emerge, such as data engineers, ETL engineers, ML engineers, and even MLOps engineers. Many tools and practices are developed and rapidly adopted. A great curated overview of open source libraries can be found in the “Awesome production machine learning” repo; other great actively evolving MLOps-supporting services include Azure Machine Learning and AWS Sagemaker.
Apart from tooling, we need to make sure companies are well aware of enterprise-grade data science components and complexities and are well equipped to face them. And that the academy is making appropriate steps toward it as well. Moreover, we ask data scientists and data engineers to be aware too and to allocate resources to approach the whole model lifecycle systematically — even if it would require a rebellion against the currently established company’s practices. And remember – even though this part of data science is resource-consuming and challenging, it is very exciting, too. At the end of the day, it is the crucial component enabling ML adoption by the enterprise.
As DataSentics’ mission is to “make data science and machine learning have a real impact on organisations across the world”, we take the challenges especially seriously. In the future blog posts of the series, we want to discuss how we approach MLOps and present the framework we adopt, enabling us and our client to bring agility to machine learning and data science solution development and delivery.
Related Sources and Further Reading
“The quest for high-quality data. Machine learning solutions for data integration, cleaning, and data generation are beginning to emerge” — by Ihab Ilyas and Ben Lorica
“Why We Need DevOps for ML Data” — by Kevin Stumpf
“2018 Trend Report: Enterprise AI Adoption. How today’s largest companies are overcoming the top challenges of AI” — by Databricks team
“Hidden Technical Debt in Machine Learning Systems” — by Google, Inc team
“MLOps: Machine Learning as an Engineering Discipline. As ML matures from research to applied business solutions, so do we need to improve the maturity of its operation processes” — by Cristiano Breuel
“MLOps: Continuous delivery and automation pipelines in machine learning” — by Google, Inc team

