 Search
Search
Use-case example: TF-IDF used for insurance feedback analysis
Consider the following scenarios: Online marketplace wants to optimise its search engine and extract important information from product descriptions. A football club wants to analyse posts on their blog. A food company wants to analyse Twitter posts about their brand new snack. An insurance company wants to know what their clients complain about in a survey.
How do you solve these problems using data science? What methods do you use?
Just one! You can get all of this done with a method called TF-IDF. What is it? How do you compute it? What problems can it solve, and where does it fall short?

In this article, we will answer all these questions for you and guide you through the whole process of TF-IDF usage.
Let’s get practical
Imagine you are the insurance company described above. We sent out a survey to improve our customer experience and immediately got three responses:
‘The online system for reporting insurance claims doesn’t work on the phone.’
‘I was surprised by the speed of resolvement of my insurance claim.’
‘I’ve been paying this expensive insurance for 10 years, but you declined my claim? Unbelievable!’
Bag of words
Because machine learning models cannot work with text data directly, we need to convert these responses into some numerical representation. We will start by transforming the text into tokens — individual words.
[ ‘The’, ‘online’, ‘system’, ‘for’, ‘reporting’, ‘insurance’, …]
[‘I’, ‘was’, ‘surprised’, ‘by’, ‘the’, ‘speed’, …]
[‘I’, ‘paid’, ‘this’, ‘expensive’, …]
Then we create a corpus — set of all the words from the responses.
[‘but’, ‘by’, ‘claim’, ‘declined’, ‘doesn’t’, ‘expensive’, … , ’the’, ‘this’, ‘Unbelievable’, ‘was’, ‘work’, ‘years’, ‘you’, ‘10’]
For each response, we mark the number of occurrences of each word.

Term frequency table of our responses
We have just created a popular text representation — bag-of-words. On top of that, we have also implemented something called TF — term frequency. Each word from the response is weighted by how many occurrences it has. Can we use this to highlight important words? Let’s try to embolden words that have high TF scores.
‘The online system for reporting insurance claims doesn’t work on the phone.’
‘I was surprised by the speed of resolvement of my insurance claim.’
‘I paid this expensive insurance for 10 years, but you declined my claim? Unbelievable!’
That doesn’t look very informative nor helpful, does it?
Some words in the responses are clearly more important than others, but by simply counting the term frequencies, we treat words like ‘insurance’, ‘for’, ‘expensive’ and ‘speed’ the same. Of course, the clients mention insurance claims, but we want to highlight the specific problems…
So what do we do about it? We could move all the common words into „stop words“ and ignore them altogether. But this would eliminate too much information and might actually be harmful.
We are smarter than that. We implement TF-IDF!
TF-IDF
This weird abbreviation stands for term frequency-inverse document frequency. It is a really cool method for information retrieval. Even though it is pretty old, it still works great!
How is TF-IDF different? It treats low-information words in a specific way. TF-IDF is basically a TF that incorporates IDF — inverse document frequency. IDF penalises words that appear too many times, allowing for a much better understanding of the point. It is something like a measure of rarity.
Let’s continue where we left on with the TF example and take a look at our responses through the optics of TF-IDF:
‘The online system for reporting insurance claims doesn’t work on the phone.’
‘I was surprised by the speed of resolvement of my insurance claim.’
‘I paid this expensive insurance for 10 years, but you declined my claim? Unbelievable!’
That looks much better than the previous example! We have pointed out the phone access to the online system, speed of resolvement and expensive but declined claim. Now we know what to improve!
How is it done?
TF-IDF is really easy to compute. The exact math formula is the following:
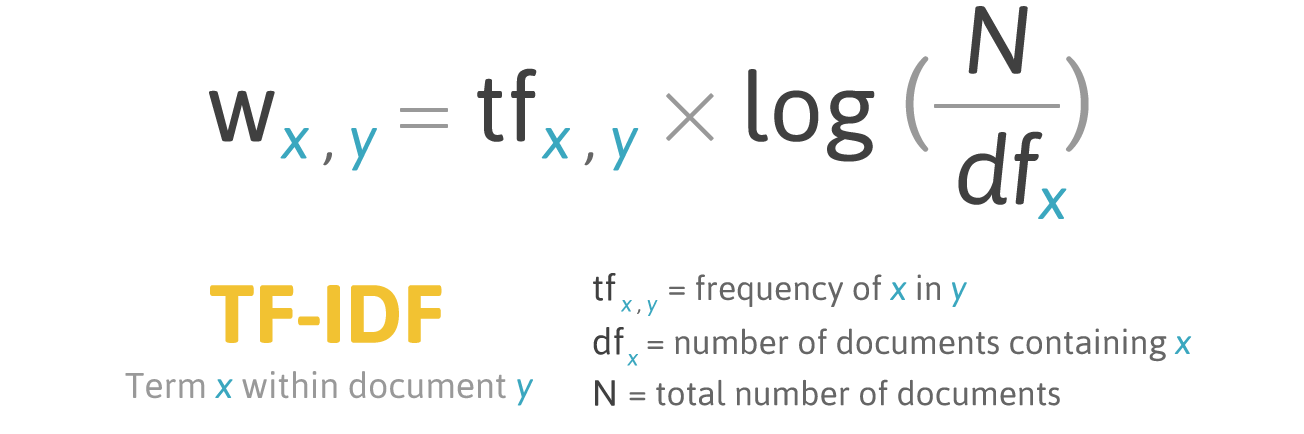
The formula for computing TF-IDF of a word in a document. Source.
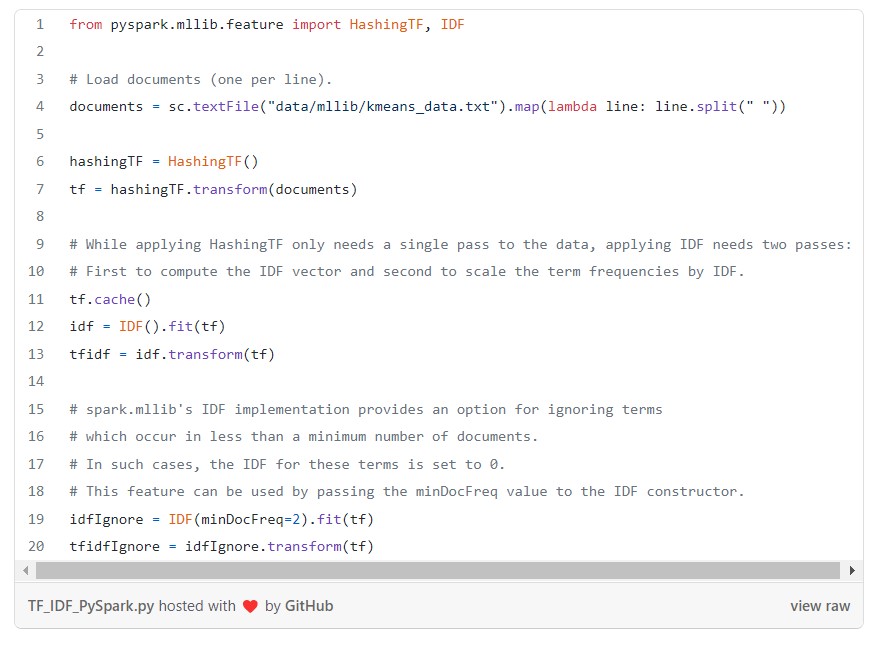
You can always take advantage of already implemented methods in PySpark or a Python library, such as Sklearn. They have made the usage even easier.
TF-IDF computation in PySpark:
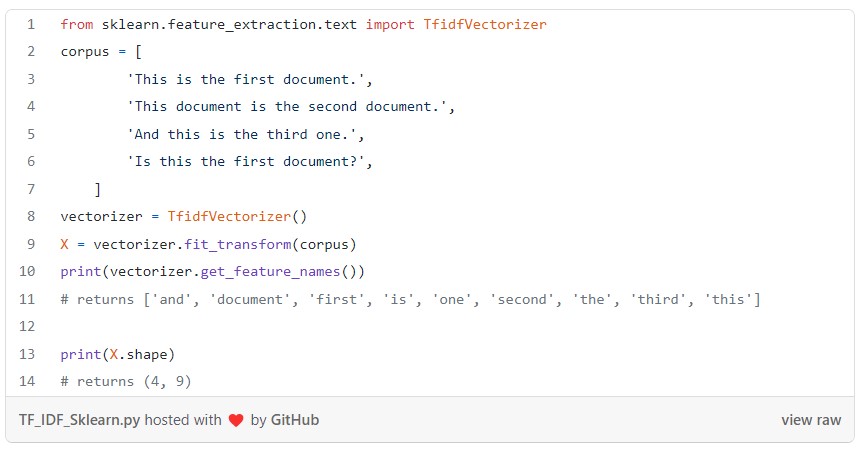
TF-IDF computation in Sklearn:
Drawbacks
Of course, life is not that simple, and TF-IDF isn‘t the answer to everything (that‘s 42 btw). It is not that important for an insurance company that a client paid for their insurance for exactly 10 years. Unique doesn’t always mean important. TF-IDF also doesn’t take the word order into account. And usually, just pure TF-IDF is not enough — you need to add things like LDA on top of it. But you get the idea, right?

