 Search
Search
How to execute a DataBricks notebook from another notebook
As in Databricks there are notebooks instead of modules; the back-end developer cannot apply the classical import and needs to use one of two ways of executing a notebook within another notebook. There are two methods of reaching this goal, and each has its pros and cons. The first method lies in using the run command, which the developer can implement to import functions and variables. As a result, the executed notebook can then access the functions and variables defined in the main machine and vice versa. But there is also the possibility of intentional override of functions and variables that can never happen while executing the dbutils.notebook.run command. It creates a new instance of the executed notebook aside from the main one. So newly called functions and variables are not reachable from the main machine. On the other hand, this method allows to pass parameter values directly to the executed notebook and create more complex solutions.

„When I was learning to code in DataBricks, it was completely different from what I had worked with so far. To me, as a former back-end developer who had always run code only on a local machine, the environment felt significantly different. I used to divide my code into multiple modules and then simply import them or the functions and classes implemented in them. But in DataBricks, as we have notebooks instead of modules, the classic import doesn’t work anymore (at least not yet). But does that mean you cannot split your code into multiple source files? Definitely not!“
-Nikola Valešová, data scientist at DataSentics
Method #1: %run command
The first and the most straightforward way of executing another notebook is by using the %run command. Executing %run [notebook] extracts the entire content of the specified notebook, pastes it in the place of this %run command and executes it. The specified notebook is executed in the scope of the main notebook, which means that all variables already defined in the main notebook prior to the execution of the second notebook can be accessed in the second notebook. And vice-versa, all functions and variables defined in the executed notebook can be used in the current notebook.
This approach allows you to concatenate various notebooks easily. On the other hand, there is no explicit way of how to pass parameters to the second notebook. However, you can use variables already declared in the main notebook.
Note that %run must be written in a separate cell. Otherwise, you won’t be able to execute it.
Here is an example of executing a notebook called Feature_engineering, which is located in the same folder as the current notebook:
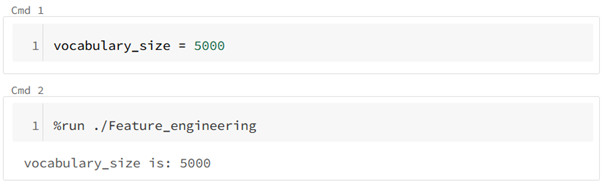
Example of the %run command
In this example, you can see the only possibility of “passing a parameter” to the Feature_engineering notebook, which was able to access the vocabulary_size variable defined in the current notebook. Note also how the Feature_engineering notebook outputs are displayed directly under the command.
Method #2: Dbutils.notebook.run command
The more complex approach consists of executing the dbutils.notebook.run command. In this case, a new instance of the executed notebook is created, and the computations are done within it, in its own scope and completely aside from the main notebook. This means that no functions and variables you define in the executed notebook can be reached from the main notebook. On the other hand, this might be a plus if you don’t want functions and variables to get unintentionally overridden.
The benefit of this way is that you can directly pass parameter values to the executed notebook and also create alternate workflows according to the exit value returned once the notebook execution finishes. This comes in handy when creating more complex solutions.
The dbutils.notebook.run command accepts three parameters:
path - relative path to the executed notebook
timeout (in seconds) - kill the notebook in case the execution time exceeds the given timeout
arguments - a dictionary of arguments that are passed to the executed notebook must be implemented as widgets in the executed notebook
Here is an example of executing a notebook called Feature_engineering with the timeout of 1 hour (3,600 seconds) and passing one argument — vocabulary_size representing vocabulary size, which will be used for the CountVectorizer model:
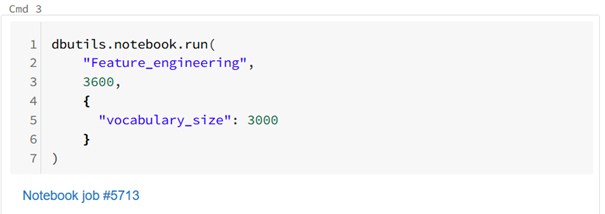
Example of the dbutils.notebook.run command
As you can see, under the command appeared a link to the newly created instance of the Feature_engineering notebook. If you click through it, you’ll see each command together with its corresponding output.
Pros and cons
Nikola prefers to use the %run command for notebooks that contain only function and variable definitions. In this case, the %run command itself takes little time to process, and you can then call any function or use any variable defined in it. This seems similar to importing modules as we know it from classic programming on a local machine, with the only difference being that we cannot “import” only specified functions from the executed notebook. Instead, the entire content of the notebook is always imported.
The drawback of the %run command is that you can’t go through the progress of the executed notebook, the individual commands with their corresponding outputs. All you can see is a stream of outputs of all commands, one by one. It can be difficult and inconvenient to debug such code in case of an error. Therefore, Nikola prefers to execute these more complex notebooks using the dbutils.notebook.run approach.
In DataSentics, some projects are decomposed into multiple notebooks containing individual parts of the solution (such as data preprocessing, feature engineering, model training) and one main notebook, which executes all the others sequentially using the dbutils.notebook.run command.
Summary
Both approaches have their specific advantages and drawbacks. The best practice is to get familiar with both of them, try them out on a few examples, and then use the more appropriate one in the individual case.
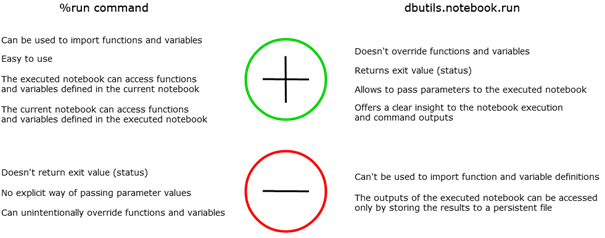
Summary of pros and cons of the individual approaches
Keep in mind that chaining notebooks by the execution of one notebook from another might not always be the best solution to a problem — the more production and space the solution requires, the more complications it could cause. On the other hand, both listed notebook chaining methods are great for their simplicity, and, even in production, there is sometimes a reason to use them. In larger and more complex solutions, it’s better to use advanced methods, such as creating a library, using BricksFlow, or orchestration in Data Factory.

