 Search
Search
Automatic Personas labelling in online marketing
To target the audience during their marketing campaigns, the business owners use keywords to include or exclude personas from their ads. DataSenics has developed a data corpus containing millions of online articles, keeping it updated according to the trends and constant changes. Thanks to the information extraction method, the system collects the existing metadata. In case of its absence, it extracts the title, keywords, and the main text from each page. As a result, DataSentics gets a set of keywords for each URL. The next step is to link this data corpus with defined interest and calculate the unigram model presenting the ratio between the count of keywords to the total amount of words.
This procedure is fully automatised and helps to find the most frequent co-appearing words. This article will show you how we employed millions of web pages to better understand personas, let data decide what defines each one, and what keywords we should use when we want to include/exclude this persona from our ads campaign.
How can Personas be used in digital marketing?
A useful personas labelling can be used mainly in two contexts, as follows:
Marketing Campaigns
The eMarketing campaigns are essential tools for business owners to tell customers about their stories, added values and the products they provide. However, there are thousands, maybe millions of businesses today conducting such campaigns every day; thus, the competition in obtaining a placeholder for your ad is rising significantly and becoming more expensive every single day.
Conducting an online marketing campaign without precise targeting of interested customers can be massively expensive. To remedy this, advertisers aim to describe their personas using a set of specific keywords.
This procedure is not sufficient for the following reasons:
- A massive set of keywords can target a very narrow audience, leading to a limited impression of the ad performance.
- A small set of keywords might describe a very general audience, leading to very low CTR (Click-Through-Rate)
- Sometimes, even domain experts can not be aware of all the related keywords because of some hidden correlation between interests. This correlation changes every day because of new trends in the culture, lifestyle, news, etc. The good news is that this correlation always appears in the online web data.
Brand Safety
Sometimes the advertisers need to avoid displaying their ads in some content that can hurt their brand. Our tool can define this unwanted content, obtain a rich set of unwanted keywords, and inject them into their eMarketing agent.
Our Method
Our method for personas labelling is 100% automated, it does not need any human expertise, and it can be easily adapted to any new market in the world.
Data
We use a considerable corpus that is developed at DataSentics; this corpus contains millions of web articles crawled from a very diverse and massive set of websites in the Czech market. We keep this corpus updated to guarantee perfect coverage and to catch new trends.
Data Pre-processing
From each page, we extract its title, keywords, and the main body text. Then, we apply statistical methods to remove noise from the main content such as header, footer, navigation menu etc.
We apply information extraction methods on each base to extract its keywords. This is done by first attempting to extract the keywords from the metadata if they exist; if not, we use another tool developed by DataSentics that automatically extracts keywords from long plain text. These keywords are enriched by word2vec model trained by us on the Czech corpus.
At the end of this process, we have a set of keywords for each URL.
Tokenisation is based on common separators that content creators use, such as comma, dash, or underscore. So if the input is “operating system, os”, then the tokens are [‘operating system’, ‘os’].
After tokenising the keywords and calculating their counts in the corpus, the most 15 frequent keywords are shown in the following pie plot:
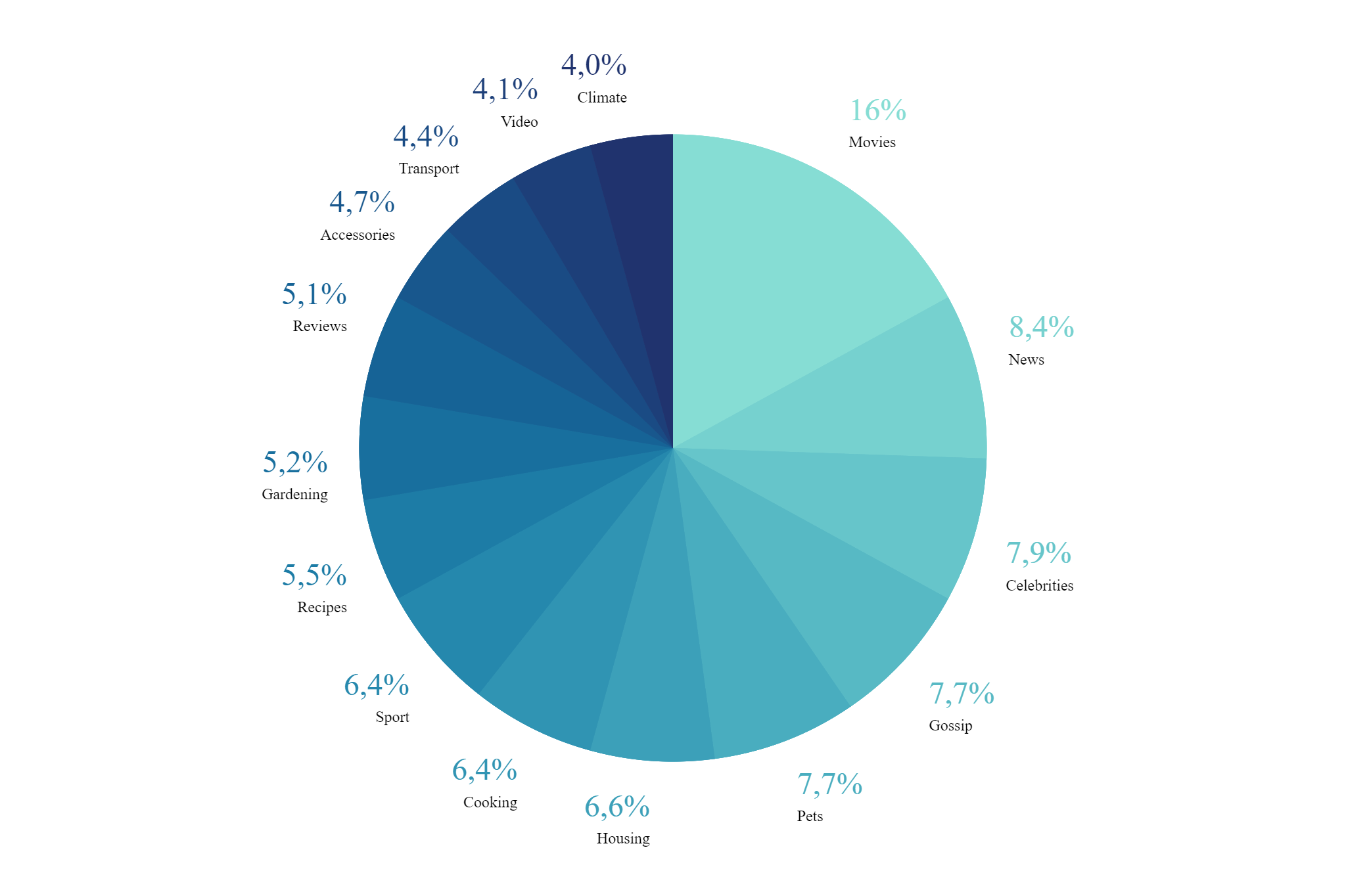
We can see from the plot that the coverage is diverse. The corpus covers pages in movies, news, sport, housing, cooking, recipes, gardening, product reviews, accessories, transport and videos.
These keywords can be personas (main interest but general ones). However, we are not only interested in these keywords - interested in what keywords appear together with them.
For example, if we think about the keyword “housing”, we can imagine other keywords such as accommodation, rental, hotels, apartments etc. And we want our model to help us capture these keywords.
Building the Personas
Our goal is to define each interest and link it with a set of keywords based on their co-occurrences in the dataset.
First, we find the most frequent words in the corpus by calculating their unigram model - the ratio between their count in the entire corpus and the total number of words.
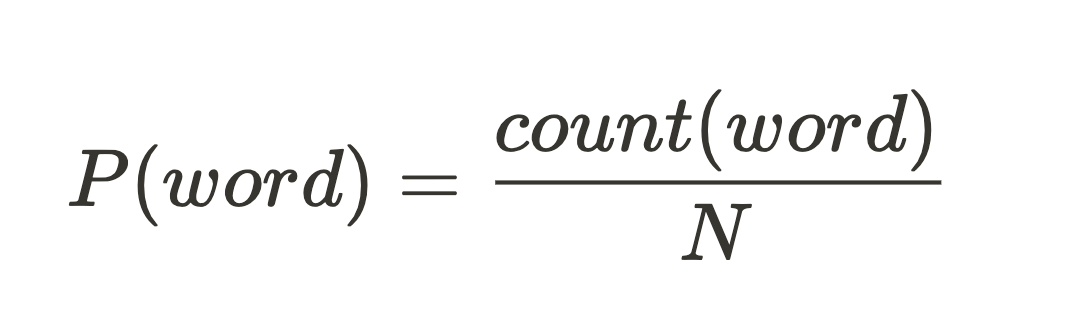
We then calculate the conditional probabilities to build the bigram model:
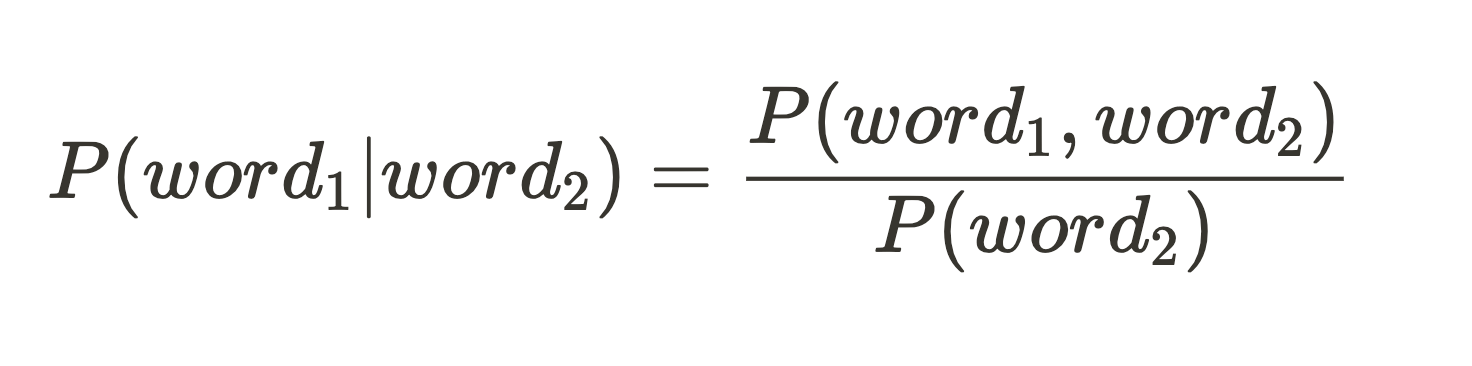
After calculating these two models, we take the top 1000 keywords according to their score from the unigram model, and then we find the most frequent words that appear together with each one.
The minor difference between these two formulas in language modelling (NLP) and in our case, is that in our case they appear together as keywords on the same page, but in language modelling, they appear next to each other (word1 followed by word2), which is not necessary in our case.
Results
This group shows a correlation between people who visit websites and articles that contain house prices and building reconstruction, saving for housing, broker consulting, etc.
ceny bytů = ['bydlení v praze','nájemní bydlení','ceny bytů v praze','airbnb','bydlení v česku','družstevní byty','pražská koalice','privatizace bytů','pronájem bytu','náklady na bydlení','raiffesen stavební spořitelna','stavební spořitelna české spořitelny','broker consulting']
Another interesting example shows how the algorithm was able to link many keywords (about 300) to the main interest (bank) such as loans, ATM, current and saving accounts, Apple pay, Google pay and almost all the famous bank names in the Czech republic.
banky =['bankovnictví','hypotéky','česká národní banka','česká spořitelna','komerční banka',......,'google pay', 'apple pay']

