 Search
Search
5 examples of AI/ML innovations bringing tangible results
Machine Learning and Artificial Intelligence are becoming fundamental in many industries, such as digital marketing, quality control, general task automation and business intelligence. Many enterprises are already leveraging these technologies to save time for their employees and take care of higher-value tasks. In this article, we will show you 5 particular examples of where AI and ML already generate tangible results.

1. Ensuring on-shelf availability
One of the biggest pains in the FMCG world is the on-shelf-availability tracking. It is highly labour demanding to take the product photos, count them, and/or browse through thousands of pictures every day. This process is also extremely prone to human errors. All the reasons mentioned above have led to the development of the Shelf Inspector application. While using computer vision and machine learning, the application analyses client pictures, detecting "objects of interest" with a 97% accuracy.
When compared to planograms, we provide out-of-stock alerts and display timelines of visits and trends over time. These features are all presented with customisable Power-BI dashboards. In addition, we analyse the competing goods and provide metrics, like shelf share. Finally, we also provide price tag analysis with alerts indicating incorrect prices, detecting promotions, and comparing competitive products. Additional client-specific metrics can be added as well, thanks to the modularity of the solution.
Since pictures are the key aspect of good detection, we have also developed an accompanying mobile app for photo collection. This is based on the feedback from the field merchandisers, who are our long-term partners. This allows us to have control over the quality of incoming photos and therefore provide the best results.
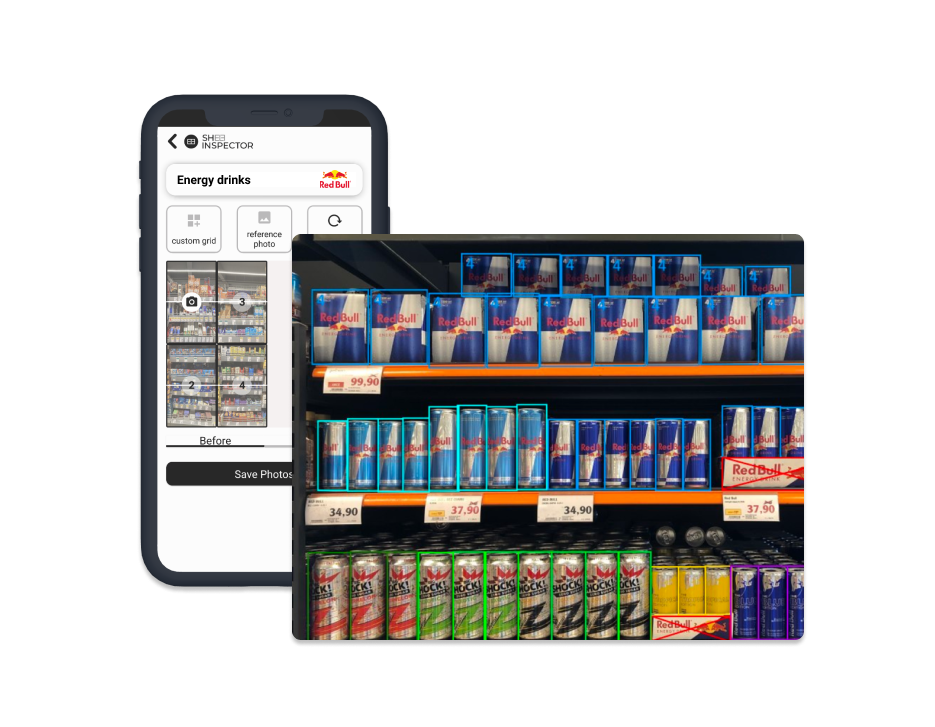
Shelf Inspector provides a complete service to tackle monitoring your product display by retail partners, from photo collection through product detections to meaningful KPI insights, all in one package.
2. Matching the best CV with every job description
Today's recruitment process is quite time-consuming. Each CV must be opened, read, and checked for a match with currently open positions. There is also a heavy reliance on human memory to keep both available candidates and job openings, especially when new candidates or openings are added. Furthermore, candidates may not share their CVs even if they are interested in your company because they do not see relevant positions today. Many organisations are therefore losing talented candidates and often have their CV databases out-of-date. Finally, people might be biased, and that could unintentionally reflect on their decision making.

Together with mBlue, we have created jobno.one, a tool that increases the processing speed of the received CVs. It ranks them autonomously, filters all relevant candidates, and fills correct fields straight into Applicant Tracking Software (ATS) or HRIS without human participation. We use parsing, comprehensive matching, and multidimensional filtering with Machine Learning and Artificial Intelligence to extract keywords from CVs and job descriptions to find the best match. This allows organisations to save an enormous amount of time while proactively recommending only the relevant vacancies to the job seekers. This is done either immediately upon sharing a CV or retrospectively when a new offer becomes available.
3. Text extraction and classification in one tool
The market leaders in current invoice reading technology have moderate accuracy and require high-quality input data (usually, electronically generated invoices or near-perfect scans).
We decided to challenge this niche and have built our own solution – the 'Invoice Reader'. It is an end-to-end, semi-supervised invoice reading solution that utilises text detection, OCR, and NLP technologies to extract and classify information from invoices.
We recognise that many times, incoming invoices might be in all shapes or forms. We tackled this challenge by building a robust solution that can process photos of printed documents, skewed photos and even handwritten text, in addition to scanned PDFs.
While the text extraction, recognition and classification technologies are constantly improving, we use a highly modular architecture to quickly upgrade or add new technologies. This way, we can keep up with the state-of-the-art models and keep our customers way ahead of the curve.

4. "Smart Data Model" - getting your data ready for ML use cases
As organisations increasingly mature and have enough data to build machine learning solutions, we see one recurring problem. In order to drive ML solutions, there is a difference between having the right data and being able to use it. This disparity comes from the fact that businesses store their data in a way decided by the technology they use, and how it is used by the business.
However, the data model needs are usually different. A layer is required to be placed between the business's data and the data used by the model. The business' data is primarily used for day-to-day insights and contains all the required data. To train the models, however, only a fraction of this data will be useful and will have to be transformed to the right granularity and state. We call this inter-layer a Smart Data Model (SDM). It contains already cleaned, parsed, and transformed data ready for consumption by the data analysts.
It is one source of truth for data-driven solutions. When the models are reviewed, everybody is then looking at the same incoming data. Creating this "one source of truth" helps solve a situation we have seen all too often – multiple departments maintain their own data in different data sources. By creating an SDM, the fruits of work of the non-cooperating departments are offered to the data analysts in one place, thus democratising the data produced by the company.

SDM also saves work – a company usually has many use cases to be solved with ML, many of which will have to go through similar data preparation steps. Due to the complexity of these tasks, the development often iterates – such as going back to feature selection and choosing different features based on model prototype review with the customer. The inter-layer must be, therefore, a flexible data format, such as the SDM. In our experience, SDM helps our customers to accelerate their development, shortens the time it takes to go back and make changes and makes the review process much easier with everybody having one source of data to fall back to.
5. Move fast when developing new models
Once SDM has been implemented and the data analysts have a one-stop-shop for all the data for building ML solutions, the next step will be a Feature store. At its core, the Feature store is a table where only features should be stored. While SDM still has to keep all the key columns to all the tables and a lot of additional data, the Feature store holds only features useful for ML models.
So instead of "Customer", "Purchases", "DateOfPurchase" columns, the feature store might hold columns such as "How many purchases have the customer made in the last 3 days?", "What month of the year is the customer most active with our products?", or "Has the customer bought any other related product?". Having these data ready leads to the ability to quickly develop prototype models – just take all the features and enter them into the model. Consequently, this promotes the ability to quickly try out solutions – especially when there are many models you want to build, without a vital requirement for their performance. Any time you create a new feature, you add it to the Feature store.
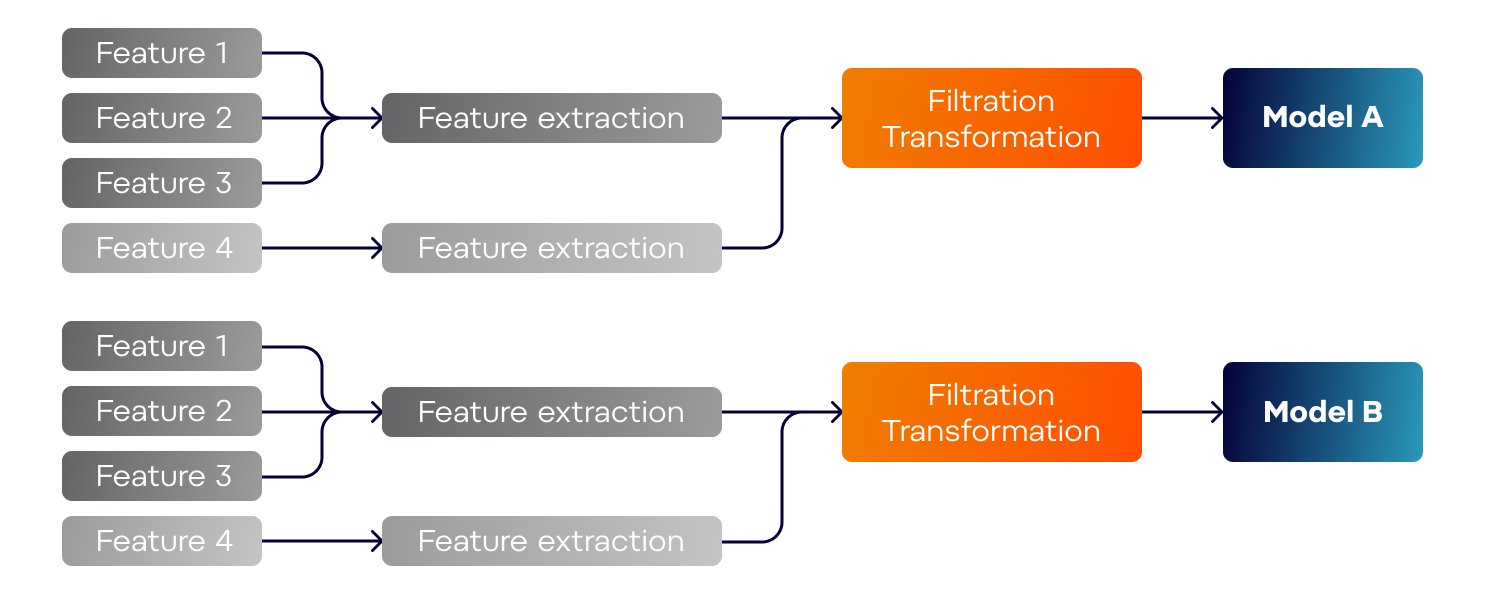
For the Feature store to be useful, it is also important to keep the history of the feature values. When you create new models and compare them to previous iterations, it is necessary to have the historical data on hand. With the Feature store implemented, the ability to reuse already prepared features makes the successful finish of new projects much easier.

